OWL (Observe, Watch, Listen): Audiovisual Temporal Context for Localizing Actions in Egocentric Videos
Abstract
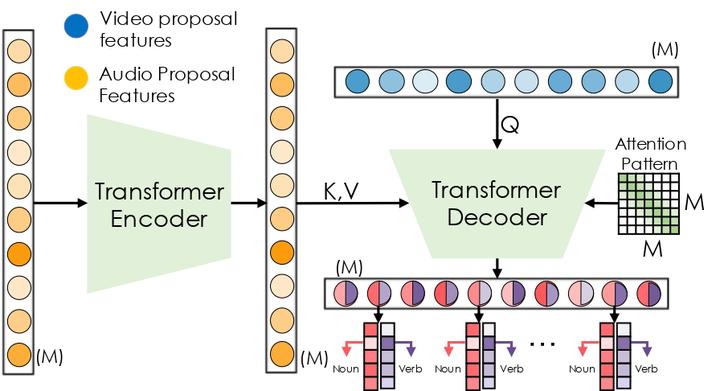
Egocentric videos capture sequences of human activities from a first-person perspective and can provide rich multi-modal signals. However, most current localization methods use third-person videos and only incorporate visual information. In this work, we take a deep look into the effectiveness of audiovisual context in detecting actions in egocentric videos and introduce a simple-yet-effective approach via Observing, Watching, and Listening (OWL). OWL leverages audiovisual information and context for egocentric Temporal Action Localization (TAL). We validate our approach in two large-scale datasets, EPIC-KITCHENS and HOMAGE. Extensive experiments demonstrate the relevance of the audiovisual temporal context. Namely, we boost the localization performance (mAP) over visual-only models by +2.23% and +3.35% in the above datasets.
Merey Ramazanova
Ph.D. Candidate at KAUST
My research interests include visual computing, videos understanding, and deep learning.