Abstract
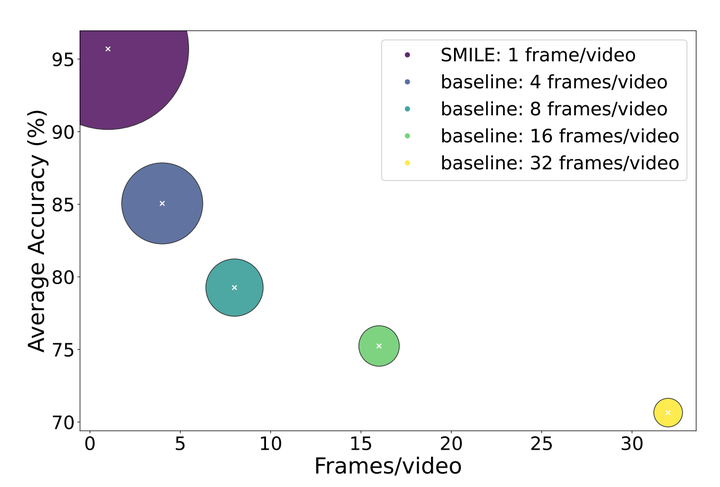
Class-incremental learning is one of the most important settings for the study of Continual Learning, as it closely resembles real-world application scenarios. With constrained memory sizes, catastrophic forgetting arises as the number of classes/tasks increases. Studying continual learning in the video domain poses even more challenges, as video data contains a large number of frames, which places a higher burden on the replay memory. The current common practice is to sub-sample frames from the video stream and store them in the replay memory. In this paper, we propose SMILE a novel replay mechanism for effective video continual learning based on individual/single frames. Through extensive experimentation, we show that under extreme memory constraints, video diversity plays a more significant role than temporal information. Therefore, our method focuses on learning from a small number of frames that represent a large number of unique videos. On three representative video datasets, Kinetics, UCF101, and ActivityNet, the proposed method achieves state-of-the-art performance, outperforming the previous state-of-the-art by up to 21.49%.
Merey Ramazanova
Ph.D. Candidate at KAUST
My research interests include visual computing, videos understanding, and deep learning.